Cornell researchers develop a novel method employing low-cost, stereo cameras that allow autonomous vehicles to detect 3D objects with a range and accuracy approaching that of LiDAR.
A group of Cornell researchers have published a paper demonstrating a new approach to object detection that shows potential to significantly reduce the cost of self-driving vehicle hardware. They achieve this by dramatically increasing the effectiveness of optical cameras for 3D object detection. In the paper, the authors suggest ways that their approach can reduce the cost and/or increase the safety of self-driving vehicles.
LiDAR Data and CNNs
In recent years it has become clear that self-driving vehicles will become a common sight on future roadways. Much of this progress has been made possible by advances in deep learning hardware and software, particularly the application of convolutional neural networks(CNNs) towards object recognition, which allows autonomous vehicles to detect nearby pedestrians, cyclists, and other vehicles. The most successful platforms thus far, such as those deployed by Waymo, have depended on expensive light detection and ranging sensors (LiDAR) to provide input for these algorithms.
Camera Output as LiDAR Data
Compared to LiDAR sensors, optical cameras are vastly cheaper to install on vehicles. There have been many attempts to use cameras as a supplementary, backup, or replacement system for object detection, but to date camera-based systems have exhibited insufficient detection accuracy to fulfill these roles.
The traditional approach to camera-based object detection analyzes an image as if one was looking through the lens of the camera. This method takes into account the color of each pixel as well as each pixel’s estimated distance from the camera. The authors of this paper overcame the perceived limitations of optical cameras by treating camera output as if it was essentially LiDAR data.
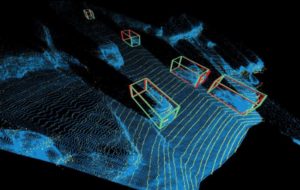
The approach demonstrated by Cornell researchers considers space as a 3D point cloud similar to LiDAR data.
Since the traditional approach already involved estimating each pixel’s distance from the camera, they simply, but very keenly, transformed these depths into a 3D point cloud before attempting object detection. Given the similarity between the camera-generated point cloud and that produced by a LiDAR sensor, the researchers were able to proceed with deep learning based object detection using the 3D vision representations as if they were, in fact, LiDAR data.

Given stereo or monocular images, a depth map is predicted, followed by back-projecting it into a 3D point cloud in the LiDAR coordinate system.
Significant Improvement Over Traditional Camera-Based Methods
The Cornell researchers’ approach scored significantly higher than other camera-based methods on the popular KITTI benchmark. A detailed review of the benchmark metrics are beyond the scope of this article. Generally, their “average precision” (AP) score doubles the score of other camera-based methods for any given KITTI scenario. Its score ranges from being 25% to 100% of that produced using LiDAR, depending on the object detection algorithm applied and the specific KITTI scenario being used.
These results are a marked improvement over previous camera-based object detection methods, but they are still short of what would be required to independently guide a self-driving vehicle on the roads. The approach presented in their paper remains important because it shows that the effectiveness of cameras as sensors is not irredeemably limited by the kind of data they produce. By changing how their output is represented to object-detection algorithms, their AP score can and will increase in the near future.
Repercussions
The repercussions of anticipated developments in camera-based object detection could lead to several innovations in autonomous vehicles. The most disruptive of these possibilities would be reducing the cost of autonomous vehicles significantly. Cameras are orders of magnitude cheaper than LiDAR sensors. While expanding the market for autonomous vehicles would surely turn the most heads, it would also demand the greatest enhancements to the specific camera-based object detection approach outlined in the Cornell research.
Combined Point Clouds and More
A more accessible milestone would be to somehow incorporate both the camera-generated and LiDAR-generated point clouds into the same object-detection pipeline. Cameras have a relatively high spatial resolution, while LiDAR has relatively high precision. In this sense, the two systems could complement each other to detect objects with a higher accuracy than what is currently possible with LiDAR alone.
Finally, improved camera-based object detection could provide a backup object-detection system for when a LiDAR-based system either malfunctions or is somehow blinded by dust or something similar. This would make autonomous vehicles more dependable in diverse, unpredictable circumstances.
Filed Under: Automotive, The Robot Report


Tell Us What You Think!