As humans age, their hearing, memory, and sharpness may fade—but not so with the rapidly emerging category of intelligent voice-controlled smart speakers. Unlike humans, the longer this category of products is around, the better they will get. Smart speakers will hear better and expand in capability. Alexa, the cloud-based voice service powering Amazon Echo’s family of devices (and others like it) are going to keep getting smarter, and their hearing will get even better as audio designers step in with more powerful, high-performing acoustic technology.
Good audio is key to better understanding
One of the next frontiers in improving vocal interaction with voice-enabled devices is the focus on higher performing audio and acoustic technology. By filtering external noise in the surrounding environment, a voice service like Amazon Alexa will hear better further away. Let’s take a look at some factors affecting smart speaker performance.
Distance, reverberation, and noise
As illustrated in Figure 1, there are three factors that affect listening performance: distance, reverberation, and noise.

Figure 1: Distance, reverberation, and noise can impact smart speaker’s ability to hear.
- Distance: A key element in performance because the farther you get from the device, the more noise in the room begins to interfere. Just moving one to three meters away, has a 10 decibel (dB) drop in sound pressure level. If Alexa were a human listener, the user’s command she would perceive drops by about half, while the noise remains the same. This is because the sound waves coming from a person’s mouth geometrically spread as they move across the room—like ripples from a stone dropped into a still pond.
- Reverberation: These ripples bounce off surfaces in the room, and arrive at slightly different times. Sounds reflect off walls, ceiling, furniture, or other objects, on its way to the device. What Alexa hears is a combination of the user’s voice propagating on a direct path to the device, along with a multiplicity of closely timed echoes. Reverberation is the persistence of sound after it’s produced. The farther you move away, the ratio of direct path voice to reverberations rapidly drops, making it harder for Alexa to understand.
- Noise: Air conditioning, kids, appliances (to mention a few) become essential to include several microphones and sophisticated voice capture algorithms.
Spectral versus spatial filtering
Before assessing how next generation smart speakers will address issues of distance, reverberation, and noise, let’s look at typical smart speaker product classes defined by coverage, distance, or environment where the device can adequately perform and interact with the user. Basic categories include:
Push button/Tap-to-Talk— can operate within one meter (arm’s length), from the user and may also include a push button trigger or tap-to-talk application.
Hands-free— can operate several meters from the user; voice is normally the primary user interface, such as in a bedroom, hallway, or other small area.
Far field— can hear and operate at five or more meters from user, and typically operates in larger spaces and noisier environments, like living rooms, kitchens, or other communal areas in the home.
To improve voice response performance, smart speaker designers implement noise suppression techniques, using multiple microphone implementations to address distance, reverberation, and noise issues. In many cases, at least two microphones are needed to receive and distinguish spatial information using noise suppression algorithms.
Noise suppression algorithms typically fall into two categories: spectral and spatial. Properly implemented, spectral noise reduction (which works by first measuring the ratio of speech-to-noise in each frequency band then removing noise appropriately) may sound good to the human ear, but be distorted when it comes to speech recognition engines. Contrarily, spatial noise reduction techniques use beamforming that can separate speech from noise based on information like direction and time of arrival.
At least two mics are required to capture required spatial information. With multiple mics, smart speakers can determine which direction the voice is coming from and differentiate between the direct path sound and noise or reverberation coming from other directions. Complex algorithms are then used to cancel or filter unwanted noise. As distance increases, the direct path sound gets weaker, compared to reverberation and noise, which stay relatively constant. This makes it more difficult for the spatial algorithm to differentiate between the direct voice and noise. To compensate, more spatial information is need, thus requiring more microphones. This is why a push- or tap-to-talk device would use fewer microphones, a hands-free device would use two to three, and a far-field implementation would have four or more (as shown in the table below).
|
Device Classification |
Distance |
Use Environment |
# of Mics |
|
Push/Tap-to-Talk |
< 1 meter |
Within arms-length, push button, or tap-to-talk trigger |
1 mic |
|
Hands-free |
1-4 meters |
Smaller areas—bedroom, hallway |
2-4 mics |
|
Far field |
5 or more meters |
Larger, communal areas—kitchen, living room |
4-7 mics |
Table 1. Number of microphones usually implemented per smart speaker device classification.
Multiple mic solutions use beamforming or spatial filtering to detect sound and determine what noise to block. More mics mean more production cost and computational power. These computations can affect battery life, which is why many smart speakers must be plugged in or remain in the charging cradle. However, this too is changing.
It’s not just the number of microphones
When purchasing next generation smart speakers, the number of microphones included won’t tell the entire story. Audio and acoustic technology once developed for professional sound systems by audio leaders, is now being developed for consumer voice-enabled devices like smart phones, speakers, and other voice-controlled applications.
Innovative techniques for locating and classifying noise sources will improve voice capture performance. Advanced audio techniques for Acoustic Echo Cancellation (AEC), coupled with multi-mic noise suppression, will also improve “barge in” performances. Barge-in allows voice commands to interrupt loud music or voice responses in progress to accurately interpret a new command.
Voice-enabled smart speakers generally use on-device keyword spotting to detect a wake word. If you’re streaming music or listening to other content, the microphones pick this up, which may completely “swamp out” your voice and make it difficult to detect the wake word. Playback detected by microphones is called echo—the louder the playback, the higher the echo. The job of AEC is to cancel this playback. The attenuation an echo incurs while propagating from speaker to microphone is called Echo Return Loss (ERL). The measurement of how much echo the AEC cancels out is called Echo Return Loss Enhancement (ERLE). Figure 2 illustrates AEC, showing a live test graph of ERLE measurement on the Cirrus Logic Alexa Voice Service (AVS) development kit console.
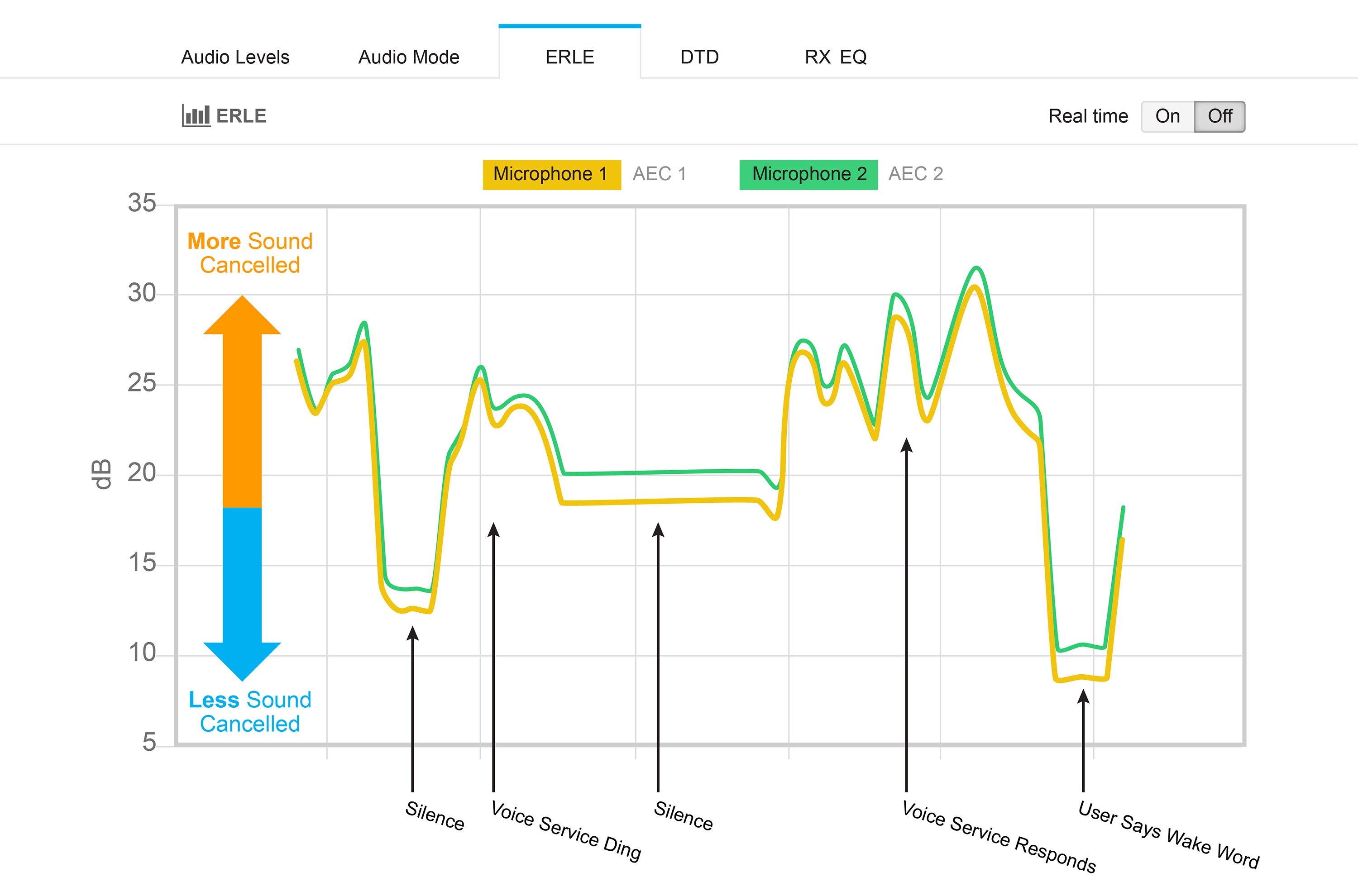
Figure 2. Test graph showing AEC functioning in a two-mic smart speaker solution.
Higher Performing Audio Leads to Better Barge-In
Another key factor to look for is audio quality in a voice-enabled device or smart speaker. There’s a direct correlation between audio quality and its responsiveness. The ability to interrupt a voice-enabled device during playback depends on the AEC capabilities and playback system. If loud playback has low distortion, it’ll sound good, but the AEC must cancel out the playback so it doesn’t interfere with device hearing calling out the wake word.
Therefore, how well a digital device works and plays music will also be a direct function of how much distortion comes from the speakers. Cheaper speakers tend to result in poorer quality audio and higher distortion playback when volume increases. Technically, the playback system can never be better than its digital-to-analog converters (DACs).
Lower power designs could open the door to new portable devices
New development kits with advanced audio functions make it easier for smart speaker OEMs to develop next generation designs and devices. Device OEMs won’t have to be acoustic experts in audio design to gain improved functionality, performance, and features coming from improved audio capabilities. OEMs will also benefit from new lower power high-performance semiconductor design.
As the use of voice response smart speakers grows, new audio and acoustic technology will improve performance and pave the way for new, innovative applications. Savvy buyers will look beyond the number of microphones, looking for high-quality audio and portability with long battery life as determining factors when purchasing next-generation voice-enabled smart speaker devices. Better acoustic technology, such as AEC, noise reduction, and low-distortion playback, will improve barge-in performance so that voice services can hear and understand you better.
Filed Under: M2M (machine to machine)