The sun may be setting on what David Letterman would call “Stupid Robot Tricks,” as intelligent machines are beginning to surpass humans in a wide variety of manual and intellectual pursuits. In March 2016, Google’s DeepMind software program AlphaGo defeated the reining Go champion, Lee Sedol. Go, a Chinese game that originated more than 3,000 years ago, is said to be googol times more complex than chess. Lee was previously considered the greatest player in the past decade with 18 world titles. Today, AlphaGo holds the ranking title.
Deconstructing how the DeepMind team was able to cross a once-impossible threshold for computer scientists could provide a primer on the tools available to roboticists. According to the AlphaGo website, “traditional AI methods, which construct a search tree over all possible positions, don’t have a chance in Go. This is because of the sheer number of possible moves and the difficulty of evaluating the strength of each possible board position.”
Instead, the researchers combined the traditional search tree approach with a deep learning system. “One neural network, the ‘policy network,’ selects the next move to play. The other neural network, the ‘value network,’ predicts the winner of the game.” However, the key of AlphaGo was having the AI go through a rigorous approach of “reinforcement learning,” where it plays itself thousands of times from the database of games.
“We showed AlphaGo a large number of strong amateur games to help it develop its own understanding of what reasonable human play looks like. Then we had it play against different versions of itself thousands of times, each time learning from its mistakes and incrementally improving until it became immensely strong.”
By October 2017, the AI became so powerful it bypassed the reinforcement learning process that contained human input of professional and amateur games to only play earlier versions of itself. The new program, AlphaGo Zero, beat the previous one that defeated Sedol months earlier by 100 games to 0, making it the greatest Go player in history. Deep Mind is now looking to apply this logic to “a wide set of structured problems that share similar properties to a game like Go, such as planning tasks or problems where a series of actions have to be taken in the correct sequence. Examples could include protein folding, reducing energy consumption or searching for revolutionary new materials.”
Reinforcement learning for physical skills
Reinforcement learning techniques are not limited to games of strategy. Researchers at the University of California’s Berkeley Artificial Intelligence Research (BAIR) Lab recently presented a paper using YouTube videos to train humanoids in mimicking movements. Utilizing a similar methodology as AlphaGo, the BAIR team developed a deep learning neural network that approximates the motion of actors seen online into programming steps for robots. “A staggering 300 hours of videos are uploaded to YouTube every minute,” the BAIR team wrote in its blog. “Unfortunately, it is still very challenging for our machines to learn skills from this vast volume of visual data.”
In order to access this treasure trove of training data, programmers today are forced to purchase and ferry around bulky motion capture (mocap) equipment to create their own demonstration videos. “Mocap systems also tend to be restricted to indoor environments with minimal occlusion, which can limit the types of skills that can be recorded,” said BAIR researchers Xue Bin (Jason) Peng and Angjoo Kanazawa. Tackling this challenge, Peng and Kanazawa set out to create a seamless AI platform for unmanned systems to learn skills by unpacking hours of online video clips.
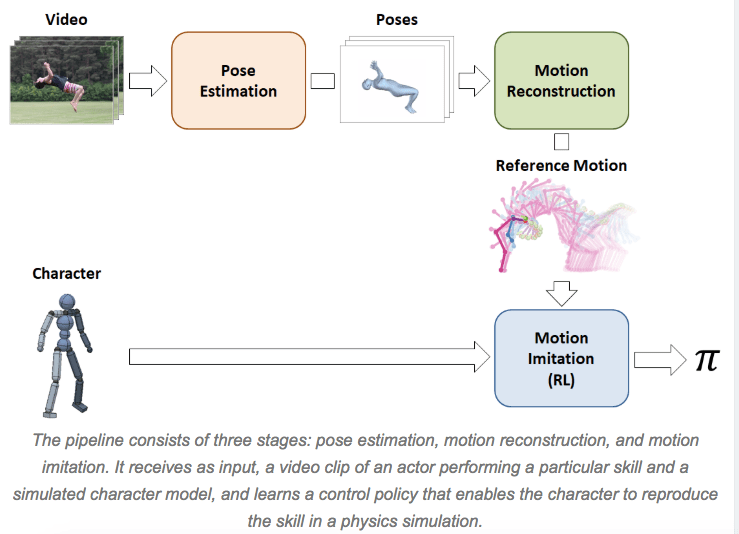
The paper states: “In this work, we present a framework for learning skills from videos (SFV). By combining state-of-the-art techniques in computer vision and reinforcement learning, our system enables simulated characters to learn a diverse repertoire of skills from video clips. Given a single monocular video of an actor performing some skill, such as a cartwheel or a backflip, our characters are able to learn policies that reproduce that skill in a physics simulation, without requiring any manual pose annotations.”
Future developments
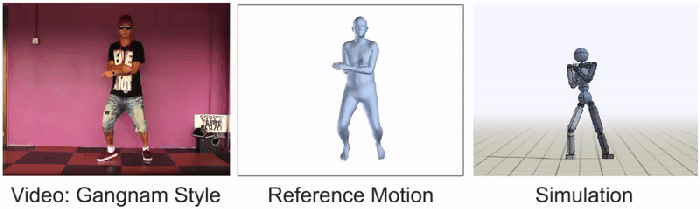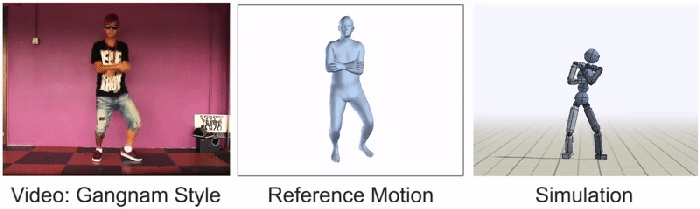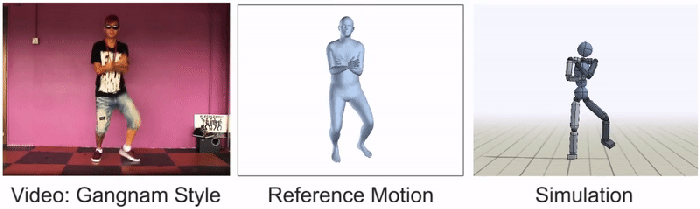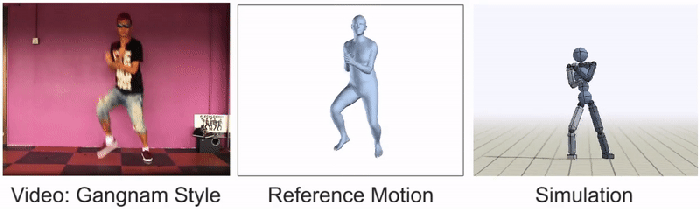
The video is fed through an agent that breaks down the movements into three stages: “pose estimation, motion reconstruction, and motion imitation.” The first stage predicts the frames following a subject initial pose. Then the “motion reconstruction” reorganizes these predictions into “reference motion.” The final process simulates the data with animated characters that continue to train via reinforcement learning. The SFV platform is actually an update to Peng and Kanazawa’s earlier system, DeepMimic, for using motion capture video. To date, the results have been staggering with 20 different skills acquired just from ordinary online videos, as shown below:
Peng and Kanazawa are hopeful that such simulations could be leveraged in the future to enable machines to navigate new environments: “Even though the environments are quite different from those in the original videos, the learning algorithm still develops fairly plausible strategies for handling these new environments.” The team is also optimistic about its contribution to furthering the development of mobile unmanned systems, “All in all, our framework is really just taking the most obvious approach that anyone can think of when tackling the problem of video imitation. The key is in decomposing the problem into more manageable components, picking the right methods for those components, and integrating them together effectively.”
Humbly, the BAIR team admits that most YouTube videos are still too complicated for their AI to imitate. Whimsically, Peng and Kanazawa single out dancing “Gangnam style” as once of these hurdles. “We still have all of our work ahead of us,” declares the researchers, “and we hope that this work will help inspire future techniques that will enable agents to take advantage of the massive volume of publicly available video data to acquire a truly staggering array of skills.”
Filed Under: The Robot Report, Robotics • robotic grippers • end effectors


Tell Us What You Think!